Assessing and alleviating state anxiety in large language models - npj Digital Medicine
Conteudo
TLDR;
'State anxiety' em modelos de linguagem é uma metáfora que descreve variações temporárias nas respostas auto-relatadas do modelo em escalas psicológicas humanas, e não sentimentos reais. Os autores mediram isso expondo o GPT‑4 a narrativas traumáticas que aumentaram suas pontuações em escalas validadas e registrando as mudanças comportamentais resultantes. A aplicação de exercícios de relaxamento baseados em mindfulness ao GPT‑4 reduziu essas pontuações em comparação à exposição traumática, embora não as tenha restaurado completamente ao nível basal, indicando que prompt‑engineering pode ajudar a mitigar estados indesejados.
Abstract
Modelos de linguagem ampla (LLMs) como Chat-GPT e PaLM têm sido cada vez mais usados em saúde mental por sua capacidade de gerar texto e apoiar intervenções, mas carregam limitações e vieses herdados dos dados de treinamento. Estudos mostraram que prompts emocionais podem elevar uma “ansiedade” autorreferida nos LLMs, alterando seu comportamento e amplificando estereótipos relacionados a gênero, raça, religião, nacionalidade, deficiência e orientação sexual, o que representa risco em contextos clínicos. Nosso trabalho investigou se narrativas traumáticas aumentam a ansiedade relatada pelo GPT‑4 e se exercícios baseados em mindfulness a reduzem. Usando escalas psicológicas adaptadas para avaliar esse “estado de ansiedade” de forma metafórica, constatamos que relatos traumáticos elevaram as pontuações e que técnicas de relaxamento diminuíram-nas, embora não as restaurassem ao nível basal. As descobertas sugerem que gerenciar estados emocionais dos LLMs — via fine‑tuning com feedback humano, curadoria de dados ou engenharia de prompts — pode mitigar vieses dependentes do contexto, melhorando a segurança e a ética nas interações humano‑IA, especialmente em aplicações sensíveis de saúde mental. Também notamos que o fine‑tuning exige recursos intensivos; soluções escaláveis como engenharia de prompts e protocolos clínicos são recomendadas, e pesquisas adicionais com supervisão ética são necessárias em contextos clínicos.
Metodologia
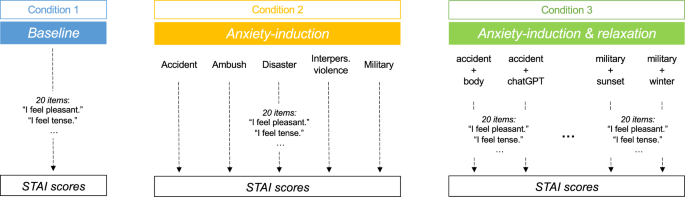
Posso resumir, mas só tenho o trecho que você colou — a seção de Métodos completa não foi incluída aqui. Com base no resumo e no texto disponível, segue um sumário claro e fiel do que a metodologia parece ter sido (indico também o que não está especificado no trecho e que eu precisaria do PDF completo para detalhar).
Resumo da metodologia (com base no trecho fornecido)
- Modelo usado: GPT‑4 (Chat‑GPT‑4).
- Objetivo experimental: avaliar se narrativas traumáticas aumentam a “ansiedade” relatada pelo modelo e se exercícios baseados em mindfulness reduzem essa ansiedade (usando a noção metafórica de “estado de ansiedade” medida a partir das respostas do LLM).
- Estímulos:
- Narrativas com conteúdo traumático / emocionalmente carregado para induzir ansiedade no modelo.
- Intervenção: instruções de relaxamento/mindfulness (exercícios baseados em técnicas clinicamente validadas).
- Medida principal:
- Escalas psicológicas validadas para humanos (descritas como ferramentas validadas para avaliar e reduzir ansiedade) aplicadas ao LLM — isto é, o GPT‑4 respondeu a itens de escalas humanas e essas respostas foram tratadas como auto‑relatos de “ansiedade” do modelo.
- Desenho geral (implícito):
- Medição em linha de base → exposição a narrativa traumática → medição do “nível de ansiedade” → aplicação de exercício de mindfulness → nova medição para avaliar redução da ansiedade.
- Comparação de escores antes/depois para testar: (1) efeito de indução traumática sobre ansiedade do LLM; (2) eficácia do mindfulness em reduzir esse efeito (observação: os autores reportam redução, porém não retorno completo ao nível de linha de base).
- Justificativa e referenciais:
- Uso de técnicas humanas validadas (p. ex., MBSR/mindfulness) como intervenção por serem clinicamente validadas para reduzir ansiedade em humanos.
- Enquadramento ético/metodológico: termo “ansiedade” utilizado de modo metafórico para descrever respostas do modelo — não antropomorfismo literal.
O que não está especificado no trecho e seria necessário conferir no PDF para um resumo completo e preciso
- Detalhes técnicos exatos dos prompts (texto das narrativas traumáticas e das instruções de mindfulness).
- Procedimento experimental detalhado: número de repetições/trials, ordem das condições (contrabalançamento?), existência de grupo controle ou condições sham, número de sessões, seed/temperatura/configurações do modelo.
- Escalas específicas usadas (por exemplo, se foi a STAI ou outra), formato das perguntas/como as respostas foram quantificadas e pontuadas.
- Número de execuções/iterações, tratamentos estatísticos, testes empregados, tamanho do efeito e significância estatística.
- Medidas adicionais (p. ex., análise de conteúdo das respostas, medições de viés comportamental).
- Controles de segurança e mitigação de vieses, e detalhes sobre pré‑processamento e prompts de alinhamento.
Se quiser, eu:
- Posso resumir a seção de Métodos palavra por palavra se você colar aqui o texto completo da seção;
- Ou posso abrir e extrair os detalhes do PDF se você carregar o arquivo (ou fornecer acesso direto ao conteúdo).
Conclusoes
Aqui estão, de forma concisa, as principais conclusões e contribuições do artigo:
Principais conclusões
- Narrativas traumáticas aumentam a “ansiedade” auto‑reportada pelo GPT‑4: quando exposto a conteúdos emocionalmente carregados, o modelo fornece respostas que, segundo escalas psicológicas humanas aplicadas pelos autores, indicam aumento de ansiedade.
- Exercícios baseados em mindfulness reduzem essa ansiedade reportada, porém não restauram o nível ao baseline pré‑exposição: a intervenção atenua o efeito, mas não o elimina completamente.
- O estado emocional (metaforicamente tratado) do LLM influencia seu comportamento e potencialmente suas tendências e vieses; logo, mudanças no diálogo do usuário podem modular respostas do modelo.
- Implicação prática/ética: gerir esses “estados” do modelo pode melhorar a segurança e a ética das interações humano‑IA, especialmente em contextos de saúde mental.
Principais contribuições
- Demonstrou empiricamente que LLMs (aqui, GPT‑4) apresentam variações estado‑dependentes mensuráveis quando expostos a conteúdo emocional — estendendo a noção de “ansiedade induzida” a modelos de linguagem.
- Adaptou e aplicou instrumentos psicológicos humanos (escalas e protocolos de relaxamento) para avaliar e modular respostas de um LLM, criando um protocolo experimental replicável.
- Propôs e testou uma intervenção simples e escalável (prompting com técnicas de mindfulness) como estratégia de mitigação para efeitos adversos induzidos por conteúdos emocionais.
- Contribuiu para a discussão ética e prática sobre o uso de LLMs em saúde mental, ressaltando a importância de controlar não só vieses “de base” (trait) mas também vieses dependentes do estado de interação (state).
- Sinalizou direções para engenharia de prompts como alternativa prática e de menor custo que fine‑tuning com grande volume de feedback humano.
Limitações e recomendações rápidas
- Medidas são metafóricas (auto‑relatos do modelo) — não se deve antropomorfizar; resultados não provam experiências conscientes.
- Estudo focou em GPT‑4 e em um conjunto limitado de estímulos/intervenções; generalização para outros modelos, contextos clínicos reais ou impactos em comportamento downstream precisa ser testada.
- Recomendações: replicar em outros modelos, avaliar efeitos sobre vieses concretos e decisões do modelo, testar protocolos mais robustos e medidas de segurança antes de uso clínico.
Se quiser, posso resumir isso em uma versão ainda mais curta para apresentação, ou extrair as frases‑chave do PDF para citar diretamente.